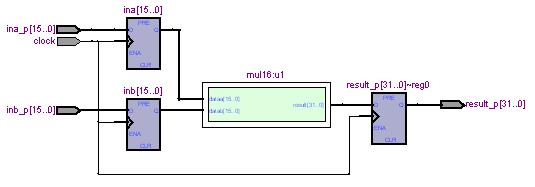
信号処理に使用される規模のFPGAであれば、通常乗算専用の論理ブロックが内部に準備されており、FPGAベンダーが提供する開発環境を用いれば、この機能を容易に利用することができます。これは、乗算専用に構成された回路ですから、論理を組むよりもはるかに効率的な処理が可能です。
そのような事情がありますので、ロジックエレメントを用いて乗算器を組むことは余り実用的ではないと思います。しかし、Verilogによる信号処理を解説するに際して、基本的な演算である乗算について触れないのも片手落ちであるようにも思われますので、以下簡単に乗算論理について解説しておきます。
乗算器はシフトと加算を組み合わせて作られます。シフト演算は論理資源を消費しませんので、多数項を加算する際の効率が乗算器の性能を決めます。
Verilogで加算を行うには“a + b”などのようにすればよく、多数の項を加算したい場合は“a + b + c + d + ……”という書き方もできます。このような形で書き下した加算モジュールのリストは以下のようになるでしょう。
module add_all(
input [15:0] in_p,
output reg [31:0] result,
input clock);
reg [15:0] in;
always @(posedge clock) begin
in <= in_p;
result <= {16'h0, in } + {15'h0, in, 1'h0} +
{14'h0, in, 2'h0} + {13'h0, in, 3'h0} +
{12'h0, in, 4'h0} + {11'h0, in, 5'h0} +
{10'h0, in, 6'h0} + { 9'h0, in, 7'h0} +
{ 8'h0, in, 8'h0} + { 7'h0, in, 9'h0} +
{ 6'h0, in, 10'h0} + { 5'h0, in, 11'h0} +
{ 4'h0, in, 12'h0} + { 3'h0, in, 13'h0} +
{ 2'h0, in, 14'h0} + { 1'h0, in, 15'h0};
end
endmodule
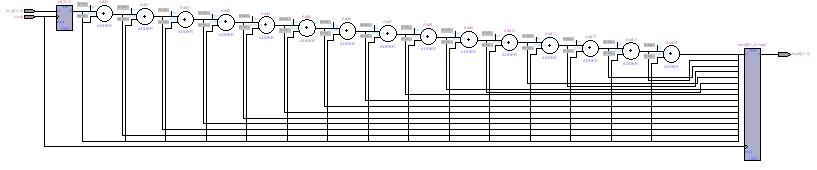
このモジュールをコンパイルして生成される信号のフロー(RTLチャート)は、下図のように加算結果に次の加算を行う形に構成され、遅れ時間が長大になります。
もちろんこれはコンパイラの問題であり、Qualtus IIでも最適化の設定を調整することでより効率的な論理を構成することもできるとは思います。しかし、何も考えずにコードを書き下した場合には、このような非効率的な論理が形成される可能性があるということは覚えておいたほうが良いでしょう。
より効率的な論理を確実に構成するには、一例を以下のリストに示すように、演算順序を規定します。この場合も、コンパイラの最適化によって、必ずしも意図したとおりの論理が構成されるとは限りませんが、より非効率にはならないであろうことは期待しても良いと思います。
module add_2step(
input [15:0] in_p,
output reg [31:0] result,
input clock);
reg [15:0] in;
wire [31:0] work0 = {16'h0, in } + {15'h0, in, 1'h0};
wire [31:0] work1 = {14'h0, in, 2'h0} + {13'h0, in, 3'h0};
wire [31:0] work2 = {12'h0, in, 4'h0} + {11'h0, in, 5'h0};
wire [31:0] work3 = {10'h0, in, 6'h0} + { 9'h0, in, 7'h0};
wire [31:0] work4 = { 8'h0, in, 8'h0} + { 7'h0, in, 9'h0};
wire [31:0] work5 = { 6'h0, in, 10'h0} + { 5'h0, in, 11'h0};
wire [31:0] work6 = { 4'h0, in, 12'h0} + { 3'h0, in, 13'h0};
wire [31:0] work7 = { 2'h0, in, 14'h0} + { 1'h0, in, 15'h0};
wire [31:0] work01 = work0 + work1;
wire [31:0] work23 = work2 + work3;
wire [31:0] work45 = work4 + work5;
wire [31:0] work67 = work6 + work7;
wire [31:0] work03 = work01 + work23;
wire [31:0] work47 = work45 + work67;
always @(posedge clock) begin
in <= in_p;
result <= work03 + work47;
end
endmodule
これをコンパイルして得られたRTLチャートは以下のようになりました。
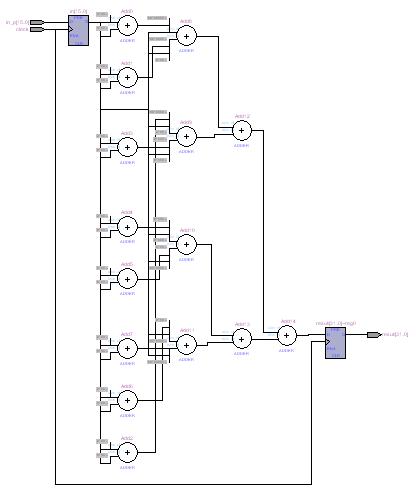
この論理は、16の入力をそれぞれ2つずつ足した8つの和を更に2つずつを足し、得られた4つの和を更に2つずつ足し、こうして得られた2つの和を加算して出力を得ています。
一度に加算する項の数をいろいろと変えてVerilogコードを書き下し、これをコンパイルした結果を下表に示します。必ずしも一様に変化しているわけではないのですが、加算を行う場合は1行に一つの加算だけを書くようにするのが、効率的な論理を形成する秘訣であるように思われます。
| モジュール名 | 加算の項数 | 最大クロック周波数 | ロジックエレメント |
| add_all | 16 | 49.83 MHz | 255 |
| add_4step | 4 | 113.92 MHz | 111 |
| add_3step | 3 | 100.62 MHz | 128 |
| add_2step | 2 | 175.87 MHz | 79 |
加算の記述が定まれば、乗算の論理は簡単に書くことができます。以下にその一例を示します。
module mul(
input [15:0] ina_p, inb_p,
output reg [31:0] result,
input clock);
reg [15:0] ina, inb;
wire [31:0] work0 = (inb[ 0] ? {16'h0, ina } : 32'h0) +
(inb[ 1] ? {15'h0, ina, 1'h0} : 32'h0);
wire [31:0] work1 = (inb[ 2] ? {14'h0, ina, 2'h0} : 32'h0) +
(inb[ 3] ? {13'h0, ina, 3'h0} : 32'h0);
wire [31:0] work2 = (inb[ 4] ? {12'h0, ina, 4'h0} : 32'h0) +
(inb[ 5] ? {11'h0, ina, 5'h0} : 32'h0);
wire [31:0] work3 = (inb[ 6] ? {10'h0, ina, 6'h0} : 32'h0) +
(inb[ 7] ? { 9'h0, ina, 7'h0} : 32'h0);
wire [31:0] work4 = (inb[ 8] ? { 8'h0, ina, 8'h0} : 32'h0) +
(inb[ 9] ? { 7'h0, ina, 9'h0} : 32'h0);
wire [31:0] work5 = (inb[10] ? { 6'h0, ina, 10'h0} : 32'h0) +
(inb[11] ? { 5'h0, ina, 11'h0} : 32'h0);
wire [31:0] work6 = (inb[12] ? { 4'h0, ina, 12'h0} : 32'h0) +
(inb[13] ? { 3'h0, ina, 13'h0} : 32'h0);
wire [31:0] work7 = (inb[14] ? { 2'h0, ina, 14'h0} : 32'h0) +
(inb[15] ? { 1'h0, ina, 15'h0} : 32'h0);
wire [31:0] work01 = work0 + work1;
wire [31:0] work23 = work2 + work3;
wire [31:0] work45 = work4 + work5;
wire [31:0] work67 = work6 + work7;
wire [31:0] work03 = work01 + work23;
wire [31:0] work47 = work45 + work67;
always @(posedge clock) begin
ina <= ina_p;
inb <= inb_p;
result <= work03 + work47;
end
endmodule
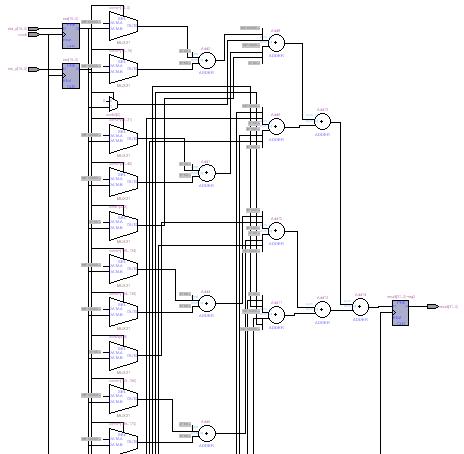
生成された論理ブロックは次のようになります。入力段が下の方に長く伸びているため、ここではほぼ上の半分のみを示しました。
シミュレーション結果を以下に示します。

上の図は小さい数の二乗を計算したものです。入力値が上限近くであった場合のシミュレーション結果を以下に示します。以下の図では数値を16進で表現しています。FFFFの二乗はFFFE0001、FFFF掛けるFFFEはFFFD0002と、上限付近の値を入力した際にも正しい計算が行われていることがわかります。

加算項数を変えた場合に乗算器の効率がどのように変わるか調べるため、上記の2項加算を行う記述の他に、4項加算を行う記述でも乗算コードを書き下して、最大クロック周波数とロジックエレメントの消費量をチェックしました。結果は下表のように、4項の加算を一つの式で与えた方が良い結果を与えております。
| モジュール名 | 加算の項数 | 最大クロック周波数 | ロジックエレメント |
| mul | 2 | 144.13 MHz | 274 |
| mul_4 | 4 | 158.10 MHz | 158 |
| mul_ip | - | >250 MHz | 0 |
上の表の最下段には、メガファンクションウィザードで形成される乗算器を使用した結果を示しています。この場合の最大クロック周波数は入出力ポートの上限で定まる250 MHzとなりました。
これは、乗算専用の回路を使用した結果であり、固定論理回路はプログラマブルな論理回路に比べて極めて高速に演算が実行できるからです。ロジックエレメントの消費量がゼロというのは異様な印象を受けるかもしれませんが、これは、乗算器とその内部のレジスタ以外には資源を消費しないという意味です。
メガファンクションウィザードで形成される乗算器を使用した場合のRTLチャートを以下に示します。非常に簡素な構成であり、乗算器以外の資源を消費せず、最大クロック周波数もきわめて高いことから、実用的な信号処理論理においては、まずこの方式で論理を組むことを考えるべきでしょう。