シミュレーション結果は次のようになりました。
前節で紹介した16ビット符号なし整数の除算モジュールは、最高周波数が21MHzとあまり速くありません。これを加速するひとつの手法が「パイプライン」と呼ばれる手法で、長い論理を中間で切り、レジスタを挿入するという手法です。
前節の16ビット符号なし整数除算モジュールは、1桁の除算モジュールを直列に16段接続していました。これを、8段ずつの二つの部分に分けて間にレジスタを挿入することとします。ソースコードは次のようになります。
module pipeline(
input [15:0] numerator_p,
input [15:0] denominator_p,
output reg [15:0] surplus_p,
output reg [15:0] quotient_p,
input clock);
wire [31:0] work1, work2;
wire[7:0] q1, q2;
reg [31:0] s1;
reg [15:0] num, den, den1;
reg [7:0] quo1;
reg den_1;
unsigned_div8 div8_1(.num8({16'h0, num}), .den8(den), .s8(work1), .q8(q1));
unsigned_div8 div8_2(.num8(s1), .den8(den1), .s8(work2), .q8(q2));
always @(posedge clock) begin
// store input port
num <= numerator_p;
den <= denominator_p;
// store result of first stage
den1 <= den;
s1 <= work1;
quo1 <= q1;
// store final result
surplus_p <= work2[31:16];
quotient_p <= {quo1, q2};
end
endmodule
ここから呼び出しているモジュールは前節で用いたものと同じですので省略します。
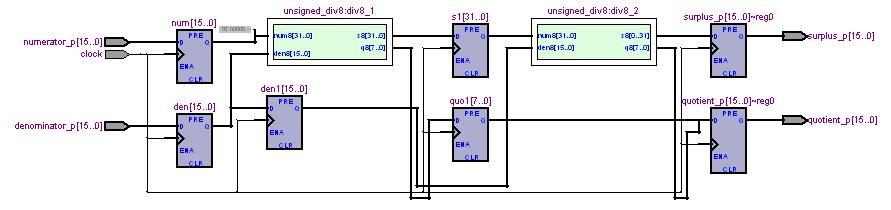
このモジュールが何をしているかは、下に示しましたRTLブロック図を見ていただければ一目瞭然でしょう。
薄緑色の二つのモジュールが8桁除算モジュールunsigned_div8で、両者の間をレジスタs1で接続しています。
このモジュールの動作は次のようになります。
まず、最初のクロックで、レジスタnumとdenに被除数と除数がセットされます。これらのレジスタの出力は、前段の8桁除算モジュールに供給されます。
二回目のクロックで、前段除算モジュールの中間結果がs1に、商の上位がquo1にセットされます。また、二回目のクロックが入力された際には、除数を納めていたレジスタdenに次に除算を行うための除数が入ってきますので、元の値をden1に退避しておきます。そして、den1とs1が後段の8桁除算モジュールに供給されます。
三回目のクロックでは、後段除算モジュールの出力する余りがレジスタsurplus_pに、後段除算モジュールの出力する商の下位と先に退避しておいた商の上位が連結されてレジスタquotient_pにセットされます。これでめでたく除算が完了したことになります。
シミュレーション結果を下図に示します。

図の左端で、クロックの立ち上がりに同期して被除数12と除数4が入力段のレジスタに取り込まれます。その次のクロックの立ち上がりでは、この演算結果は中間レジスタに取り込まれ、出力段には一つ前の演算結果が現れます。そして、入力取り込み後2つ目のクロックの立ち上がりの後に、これらを除算した結果である商3と余り0が出力レジスタにセットされます。
シミュレーションでは、小さい側の演算例として12/13の結果である「0余り12」までと、大きい側の演算例として65535/65535、65535/65534、65535/65533、65534/65535、65533/65535の結果を示していますが、いずれも正常に演算が行われることがわかりました。
タイミング解析の結果では、パイプライン処理にした場合の最高クロック周波数は42MHzとなりました。これは、パイプライン化を行わない場合の最高クロック周波数21MHzのちょうど2倍です。この結果は、論理の段数を半分にしてレジスタ間に入れましたので、当然ともいえる結果です。さらに高いクロック周波数とするためには、8桁の除算モジュールを二つ使う代わりに4桁の除算モジュールを4つ使用して、それぞれの間にレジスタを置くことで、最高クロック周波数を更に倍近くまで上げることができます。
論理をパイプライン化することにより、クロック周波数を上げることができ、同じ時間内により多くの除算を実行することができます。ただし、入力が与えられてから出力が現れるまでの所要時間は、クロック数が増加するために、なんら短縮はされません。これは、除算を行うためにはどのような形であれ16段の1桁除算回路を通過する必要があることから、当然の結果ともいえます。
ステートマシンとは、「状態が遷移して各状態で異なる動作をする装置」の総称なのですが、こういわれてしまいますと何のことかわからなくなります。簡単な例では「クロック信号でカウンタをインクリメントし、カウンタの値によって異なる動作をする装置」がその一例です。
まず、16ビット符号なし除算器を4つの状態をとるステートマシンとして構成した例をブロック図でご紹介しましょう。
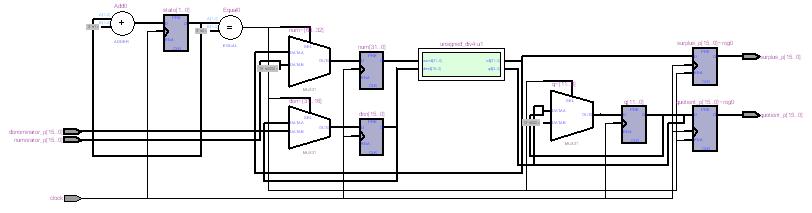
上に示しましたのがそのブロック図で、中央にありますのは16ビット符号なし除算を4桁分実行するモジュールunsigned_div4です。状態数4のステートマシンとして16ビット除算器を構成する場合、4桁の除算器ただ一つあればよく、これを4回使いまわすことになります。
上のブロック図の左上にありますのが、ステートマシンの要、2ビットカウンタで、クロック信号clockによりインクリメントされて0から3までの4つの状態をとります。
4桁除算モジュールの入力側には被除数numと除数denを格納するためのレジスタが設けられています。ステート0では、これらのレジスタには入力された被除数numerator_pと除数denominator_pがセットされます。その他のステートではレジスタdenは値を変えず(図では出力が入力にフィードバックされています)、レジスタnumは除算器の出力である中間結果がセットされます。
また、それぞれのステートの後で除算器が出力する各桁の商(4ビットずつ)は、右側にありますシフトレジスタqにセットされます。レジスタqの前に置かれたマルチプレクサはステート0でレジスタqをクリアするためのものですが、4回4ビットのシフトを行えば前回の結果はすべてシフトアウトされますので、この操作は余計であったかもしれません。
ソースリストを以下に示します。ここで使用しているサブモジュールも、すべて前節で用いたものと同じです。
module div_4_state(
input [15:0] numerator_p,
input [15:0] denominator_p,
output reg [15:0] surplus_p,
output reg [15:0] quotient_p,
input clock);
reg [1:0] state;
reg [31:0] num;
reg [15:0] den, q;
wire [31:0] s4;
wire [3:0] q4;
unsigned_div4 u1(.num4(num), .den4(den), .s4(s4), .q4(q4));
always @(posedge clock) begin
state <= state + 2'h1;
case (state)
2'h0: begin
num <= {16'h0, numerator_p};
den <= denominator_p;
q <= 16'h0;
quotient_p <= {q[11:0], q4};
surplus_p <= s4[31:16];
end
default: begin
num <= s4;
q <= {q[11:0], q4};
end
endcase
end
endmodule
シミュレーション結果は次のようになりました。

今回は8クロックごとに入力信号を変化させています。クロック信号が非常に狭くわかりにくいのですが、5クロック遅れて演算結果が出力されている様子がおわかりいただけますでしょうか。
この構成の最高クロック周波数は87MHzとなりました。これは、何もしない場合の最高クロック周波数21MHzのほぼ4倍、パイプライン化したときの最高クロック周波数42MHzのほぼ2倍です。これは、この例で使用している除算器が4桁除算器であり、内部の論理段数がパイプラインの例で使用した除算器の1/2であることによります。ただし、この例では4クロックが内部の繰り返し処理に使用されており、入力が確定してから出力が現れるまでの最短時間は、いずれの例でも同等となります。
ステートマシンとして除算器を構成したときの他との最大の違いは、装置構成に必要なロジックエレメントの数が格段に減少することです。何もしない場合の16ビット符号なし除算器に必要なロジックエレメントの総数は543でしたが、パイプライン化した場合の総数は549と、レジスタを挿入した分が増加しています。これに対して、ステートマシンとして構成した場合のロジックエレメントの総数は191と格段に減少します。これは、一つの4桁の除算器を4回使用しているからで、除算を行う論理部分でのロジックエレメント消費量は1/4に減らすことができるからです。
パイプライン化とステートマシン化には、それぞれ特失があります。ステートマシン化した場合は、ロジックエレメントの消費量を減らすことができ、クロック周波数もパイプライン化した場合と同様に上げることができます。しかし、上の例では、入力を取り込むのは4クロックに1回であり、単位時間内に処理できるデータ数は変化しません。これに対して、パイプライン化した場合は、ロジックエレメントの消費量が多少増加するというマイナスはあるものの、クロック周波数が上がった分だけ単位時間内に処理できるデータ数が増加します。
これらいずれの技法を採用するかは、処理できるデータ数を増やしたいのか、それともロジックエレメントを削減したいのかによって判断されるべきでしょう。
パイプラインとステートマシンに関するVerilog-2001のソースコードをこのファイルに置きました。